Deploy is not the same as release

A lot of people think it’s risky to deploy software. Some of these people lose sleep over deploying software. A lot of people have jobs based around deploying software, and for them others they work with, it is a big deal. It involves a lot of something people call “technical risk management”. That’s just a fancy phrase for “if we make this big change, will it all go wrong and blow up in our faces”.
But the thing is, there’s a trick. There is actually a big difference between deploying software and releasing software. That’s what a lot of people don’t realise. That deploy is not the same as release. That the old traditional ITIL ways of doing and talking about releases are becoming outdated and irrelevant. Smart companies are doing technical risk management better by separating deployment and release.
What is ITIL anyway?
ITIL stands for IT Infrastructure Library. It’s a traditional way of doing IT Service Management. IT Service Management is all of the activities that happen for a system after it’s been built: deploying it, changing it, breaking it, fixing it, and so on. One of the ITIL disciplines is Release Management. It basically says you package a bunch of changes into a big thing called a Release (this is already sounding bad, shouldn’t we be doing lots of small changes, if we want to be Agile, ala Continuous Delivery?).
Since a release involves moving software from a non-production environment (where customers don’t use it) to a production environment (where customers do use it), this involves a lot of risk.
So we have to carefully test deployment scripts, rollback scripts, configurations, and so on. And releases generally involve lots of people coming into work at 2am and drinking lots of bad coffee and looking at server logs and incident reports and pointing and shouting and trying to get the big release working so customers can start using the shiny new software right away.
What was wrong with that way of doing release management?
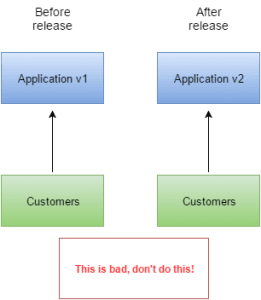
Traditional release management. Much risk, such bad!
There’s a lot wrong with doing releases this way.
First of all, it bundles many small changes into a big release. Lean principles say that small batch size is better, always better, and the smaller the better. It reduces risk and improves lead time. Secondly, it pushes all of those changes onto all of your customers at once, which is a big risk and is quite unnecessary. It gives you no time to verify your production changes before they go out to customers.
Fundamentally, it assumes that deploying software and releasing it is the same thing. But it isn’t necessarily so.
What is a better more agile / DevOps way of doing releases?
One way of reducing the risk of a big release is to break it up into many small changes that are released frequently. But there are other tools and approaches, too, and they involve how customers start using software. The key point is this: just because the software has been deployed to production doesn’t mean that it has been released to customers.
But isn’t software released to customers once it has been pushed to production infrastructure?
No that is not necessarily so at all. There are few useful approaches you can use to split these concepts out.
Piloting

Piloting. A bit more work, much less risk.
The idea here is that only certain customers get put on new versions of the software. They are in your “pilot” group. So when a customer logs in or goes to your website, a pilot lookup is performed. And the customer goes to the new software only if they are in the pilot group. Once everyone is happy with how the new software works, you do a “hard launch” and put everyone into the pilot group (which effectively ends the pilot group since it’s now the normal group) and announce it officially. You can start with a small internal (staff) pilot, or a small customer pilot, and start “dialling up” slowly or more quickly, however you like.
Versioning
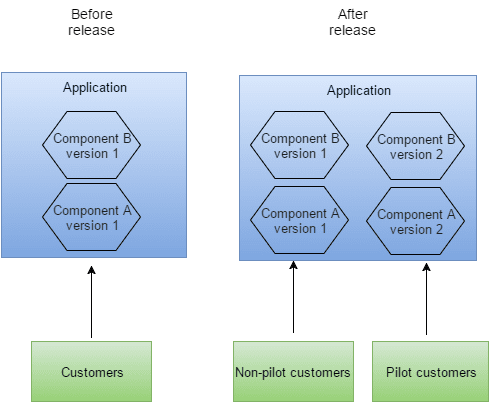
Versioning is cool. Kind of requires microservices. Which are also cool.
Versioning is similar to piloting but works not just with brand new components (i.e. most customers see features A and B, but pilot group people see features A, B and C), but it also works with new versions of existing components. You deploy multiple versions of your components and have them existing side-by-side in production.
So some customers, when they go to your site or use your app, will be using version 1.0 of a certain component, some will be using version 1.1, some will be using maybe an experimental version 2, and so on.
If you want to be really smart, you can break your whole application into many small services, each of which can be independently versioned and deployed and piloted separately. This is called Micro-services, and all the cool kids are doing it. Really. I’ll write more about this soon. But you need to start learning about microservices if you don’t already know.
Blue-green deployments
This is a simple but very effective way of doing technical risk management (it’s much easier to get going than microservices, which is a major architectural change).
You basically have two instances of production: blue, and green (you can call them whatever you want, it doesn’t matter). Customers are currently say going to the “blue” version of your site / app / whatever. Instead of doing a big-bang release that replaces the blue site with a newer blue site, you just deploy a “green” site. Everybody is still going to the blue site.
You then gradually start shifting traffic from the “blue” site to the “green” site. Kind of like piloting. This can be done in a few ways, but is often done at the load balancer level. You get your load balancer to divert a certain percentage of traffic from the blue site to the green site.
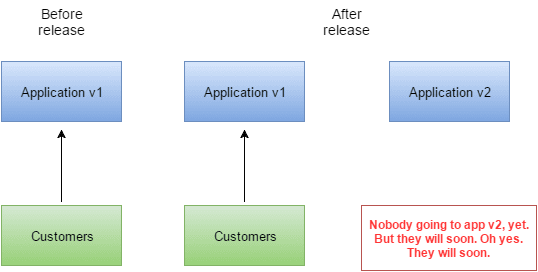
Blue green deployments. Simples!
The advantage is that it is quite simple and you don’t have to worry about pilot groups or microservices or versioning or anything. You just basically have two versions: “old” and “new”.
The disadvantages are you can’t easily control who is piloting the new version and who is on the old version. That’s because load balancers don’t know who you are, they just bounce traffic around. The other disadvantage is that depending on how your application is structured, you might have to be careful with site affinity (i.e. once a user gets bounced to a particular site, the balancer has to ensure all their remaining requests for that session go to that site, or you could get some very weird behaviour).
